If asked how your email sorted spam emails from legitimate emails, what would you say? Do you think you could build a spam filter yourself?
Hidden throughout our lives is one of the most prevalent uses for machine learning: text classification. Text classification allows us to do everything from identifying spam emails to being able to convert hand-written words into their plain text, digital equivalent.
In this tutorial, we’re going to discover how we can use the Naive Bayes technique to build our own text classification and build a spam filter using Python.
If you’re ready to expand how you see the digital world and text, let’s jump in!
Intro to Text Classification
The challenge of text classification is to attach labels to bodies of text, e.g., tax document, medical form, etc. based on the text itself. For example, think of your spam folder in your email. How does your email provider know that a particular message is spam or “ham” (not spam)? We’ll take a look at one natural language processing technique for text classification called Naive Bayes.
Download the full code here.
BUILD GAMES FINAL DAYS: Unlock 250+ coding courses, guided learning paths, help from expert mentors, and more.
Bayes Theorem
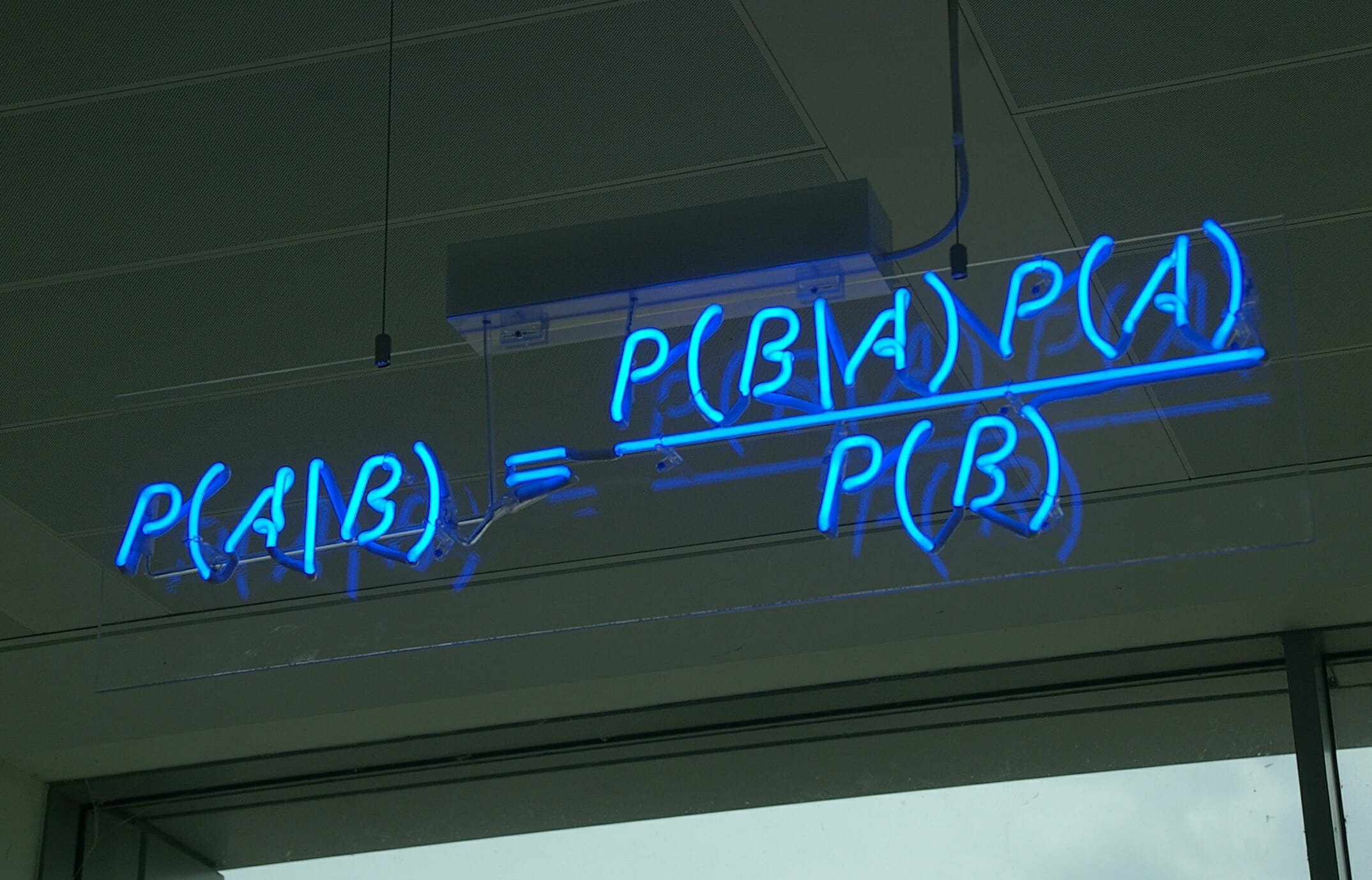
(credit: https://en.wikipedia.org/wiki/Bayes%27_theorem#/media/File:Bayes%27_Theorem_MMB_01.jpg)
Before we derive the algorithm, we need to discuss the fundamental rule that Naive Bayes uses: Bayes Theorem:
\[ p(A|B) = \displaystyle\frac{p(B|A)p(A)}{p(B)} \]
where $A$ and $B$ are events and $p(\cdot)$ is a probability.
Let’s take a second to break this down. On the left, we have the probability of an event $A$ happening given that event $B$ happens. We say this is equal to the probability of event $B$ happening given event $A$ times the probability that event $A$ happens overall. All of that is divided by the probability that event $B$ happens overall. An example of this might help shed some light on why this is an ingenious theorem.
The classic example used to illustrate Bayes Theorem involves medical testing. Let’s suppose that we were getting tested for the flu. When we get a medical test, there are really 4 cases to consider when we get the results back:
- True Positive: The test says we have the flu and we actually have the flu
- True Negative: The test says we don’t have the flu and we actually don’t have the flu
- False Positive: The test says we have the flu and we actually don’t have the flu
- False Negative: The test says we don’t have the flu and we actually do have the flu
Suppose we also know some information about the flu and our testing methodology: we know our test can correctly detect that a person has the flu 99.5% of the time (i.e., $p(\text{+}|\text{Flu})=0.995$) and correctly detect that a person does not have the flu 99.5% of the time (i.e., $p(\text{-}|\text{No Flu})=0.995$). These correspond to the true positive rate and true negative rate. We also know that this specific type of flu is rare and only affects 1% of people. Given this information, we can compute the probability that any randomly selected person will have this specific type of the flu. Specifically, we want to compute the probability that the person has the specific type of flu, given that the person tested positive for it, i.e., event $A=\text{Flu}$ and $B=\text{+}$.
Let’s just substitute the problem specifics into Bayes Theorem.
\[ p(\text{Flu}|\text{+}) = \displaystyle\frac{p(\text{+}|\text{Flu})p(\text{Flu})}{p(\text{+})} \]
Now let’s try to figure out specific values for the quantities on the right-hand side. The first quantity is $p(\text{+}|\text{Flu})$. This is the probability that someone tests positive given that they have the flu. In other words, this is the true positive rate: the probability that our test can correctly detect that a person has the flu! This number is 99.5% or 0.995 The next quantity in the numerator is $p(\text{Flu})$. This is called the prior probability. In other words, it is the probability that any random person has the flu. We know from our problem that this number is 1%, or 0.01. Let’s substitute in those values in the numerator.
\[ p(\text{Flu}|\text{+}) = \displaystyle\frac{0.995 \cdot 0.01}{p(\text{+})} \]
Now we have to deal with the denominator: $p(\text{+})$. This is the probability that our test returns positive overall. We can’t quite use the information given in the problem as directly as before however. But first, why do we even need $p(\text{+})$? Recall that probabilities have to be between 0 and 1. Based on the above equation, if we left out the denominator, then we wouldn’t have a valid probability!
Anyways, when can our test return positive? Well there are two cases: either our test returns positive and the person actually has the flu (true positive) or our test returns positive and our person does not have the flu (false positive). We can’t quite simply sum both of these cases to be the denominator. We have to weight them by their respective probabilities, i.e., the probability that any person has the flu overall and the probability that any person does not have the flu overall. Let’s expand the denominator.
\[ p(\text{Flu}|\text{+}) = \displaystyle\frac{0.995 \cdot 0.01}{p(\text{+}|\text{Flu})p(\text{Flu})+p(\text{+}|\text{No Flu})p(\text{No Flu})} \]
Now let’s reason about these values. $p(\text{+}|\text{Flu})p(\text{Flu})$ is something we’ve seen before: it’s the numerator! Now let’s look at the next quantity: $p(\text{+}|\text{No Flu})p(\text{No Flu})$. We can compute the first term by taking the complement of the true negative: $p(\text{+}|\text{No Flu})=1-p(\text{-}|\text{No Flu})=0.005$. And $p(\text{No Flu})=1-p(\text{Flu})=0.99$ since they are complimentary events. So now we can plug in all of our values and get a result.
\[ p(\text{Flu}|\text{+}) = \displaystyle\frac{0.995 \cdot 0.01}{0.995 \cdot 0.01+0.005 \cdot 0.99}= 0.6678\]
This result is a little surprising! This is saying, despite our test’s accuracy, knowing someone tested positive means that there’s only a 67% chance that they actually have the flu! Hopefully, this example illustrated how to use Bayes Theorem.
Deriving Naive Bayes
Now let’s convert the Bayes Theorem notation into something slightly more machine learning-oriented.
\[ p(H|E) = \displaystyle\frac{p(E|H)p(H)}{p(E)} \]
where $H$ is the hypothesis and $E$ is the evidence. Now this might make more sense in the context of text classification: the probability that our hypothesis is correct given the evidence to support it is equal to the probability of observing that evidence given our hypothesis times the prior probability of the hypothesis divided by the probability of observing that evidence overall.
Let’s break this down again like we did for the original Bayes Theorem, except we’ll use the context of the text classification problem we’re trying to solve: spam detection. Our hypothesis $H$ is something like “this text is spam” and the evidence $E$ is the text of the email. So to restate, we’re trying to find the probability that our email is spam given the text in the email. The numerator is then the probability that that we find these words in a spam email times the probability that any email is spam. The denominator is a bit tricky: it’s the probability that we observe those words overall.
There’s something a bit off with this formulation though: the evidence needs to be represented as multiple pieces of evidence: the words $w_1,\dots,w_n$. No problem! We can do that and Bayes Theorem still holds. We can also change hypothesis $H$ to a class $\text{Spam}$.
\[ p(\text{Spam}|w_1,\dots,w_n) = \displaystyle\frac{p(w_1,\dots,w_n|\text{Spam})p(\text{Spam})}{p(w_1,\dots,w_n)} \]
Excellent! We can use a conditional probability formula to expand out the numerator.
\[ p(\text{Spam}|w_1,\dots,w_n) = \displaystyle\frac{p(w_1|w_2,\dots,w_n,\text{Spam})p(w_2|w_3,\dots,w_n,\text{Spam})\dots p(w_{n-1}|w_n,\text{Spam})p(\text{Spam})}{p(w_1,\dots,w_n)} \]
Not only does this look messy, it’s also quite messy to compute! Let’s think about the first term: $p(w_1|w_2,\dots,w_n,\text{Spam})$. This is the probability of finding the first word, given all of the other words and given that the email is spam. This is really difficult to compute if we have a lot of words!
Naive Bayes Assumption
To help us with that equation, we can make an assumption called the Naive Bayes assumption to help us with the math, and eventually the code. The assumption is that each word is independent of all other words. In reality, this is not true! Knowing what words come before/after do influence the next/previous word! However, making this assumption greatly simplifies the math and, in practice, works well! This assumption is why this technique is called Naive Bayes. So after making that assumption, we can break down the numerator into the following.
\[ p(\text{Spam}|w_1,\dots,w_n) = \displaystyle\frac{p(w_1|\text{Spam})p(w_2|\text{Spam})\dots p(w_n|\text{Spam})p(\text{Spam})}{p(w_1,\dots,w_n)} \]
This looks better! Now we can interpret a term $p(w_1|\text{Spam})$ to mean the probability of finding word $w_1$ in a spam email. We can use a notational shorthand to symbolize product ($\Pi$).
\[ p(\text{Spam}|w_1,\dots,w_n) = \displaystyle\frac{p(\text{Spam})\displaystyle\prod_{i=1}^np(w_i|\text{Spam})}{p(w_1,\dots,w_n)} \]
This is the Naive Bayes formulation! This returns the probability that an email message is spam given the words in that email. For text classification, however, we need an actually label, not a probability, so we simply say that an email is spam if $p(\text{Spam}|w_1,\dots,w_n)$ is greater than 50%. If not, then it is not spam. In other words, we choose “spam” or “ham” based on which one of these two classes has the higher probability! Actually, we don’t need probabilities at all. We can forget about the denominator since its only purpose is to scale the numerator.
\[ p(\text{Spam}|w_1,\dots,w_n) \propto p(\text{Spam})\displaystyle\prod_{i=1}^np(w_i|\text{Spam}) \]
(where $\propto$ signifies proportional to) That’s one extra thing we don’t have to compute! In this instance, we pick whichever class has the higher score since this is not a true probability anymore.
Numerical Stability
There’s one extra thing we’re going to do to help us with numerical stability. If we look at the numerator, we see we’re multiplying many probabilities together. If we do that, we could end up with really small numbers, and our computer might round down to zero! To prevent this, we’re going to look at the log probability by taking the log of each side. Using some properties of logarithms, we can manipulate our Naive Bayes formulation.
\begin{align*}
\log p(\text{Spam}|w_1,\dots,w_n) &\propto \log p(\text{Spam})\displaystyle\prod_{i=1}^np(w_i|\text{Spam})\\
\log p(\text{Spam}|w_1,\dots,w_n) &\propto \log p(\text{Spam}) + \log \displaystyle\prod_{i=1}^np(w_i|\text{Spam})\\
\log p(\text{Spam}|w_1,\dots,w_n) &\propto \log p(\text{Spam}) + \displaystyle\sum_{i=1}^n \log p(w_i|\text{Spam})
\end{align*}
Now we’re dealing with additions of log probabilities instead of multiplying many probabilities together! Since log has really nice properties (monotonicity being the key one), we can still take the highest score to be our prediction, i.e., we don’t have to “undo” the log!
Dataset
We’ll be using the Enron email dataset for our training data. This is real email data from the Enron Corporation after the company collapsed. Before starting, download all of the numbered folders, i.e., enron1, enron2, etc., here and put all of them in a top-level folder simply called enron. Put this enron folder in the same directory as your source code so we can find the dataset!
A WORD OF WARNING!: Since this dataset is a real dataset of emails, it contains real spam messages. Your anti-virus may prune some these emails because they are spam. Let your anti-virus prune as many as it wants. This will not affect our code as long as there are some spam and ham messages still there!
Naive Bayes Code
Here is the dataset-loading code:
import os import re import string import math DATA_DIR = 'enron' target_names = ['ham', 'spam'] def get_data(DATA_DIR): subfolders = ['enron%d' % i for i in range(1,7)] data = [] target = [] for subfolder in subfolders: # spam spam_files = os.listdir(os.path.join(DATA_DIR, subfolder, 'spam')) for spam_file in spam_files: with open(os.path.join(DATA_DIR, subfolder, 'spam', spam_file), encoding="latin-1") as f: data.append(f.read()) target.append(1) # ham ham_files = os.listdir(os.path.join(DATA_DIR, subfolder, 'ham')) for ham_file in ham_files: with open(os.path.join(DATA_DIR, subfolder, 'ham', ham_file), encoding="latin-1") as f: data.append(f.read()) target.append(0) return data, target
This will produce two lists: the data list, where each element is the text of an email, and the target list, which is simply binary (1 meaning spam and 0 meaning ham). Now let’s create a class and add some helper functions for string manipulation.
class SpamDetector(object):
"""Implementation of Naive Bayes for binary classification"""
def clean(self, s):
translator = str.maketrans("", "", string.punctuation)
return s.translate(translator)
def tokenize(self, text):
text = self.clean(text).lower()
return re.split("\W+", text)
def get_word_counts(self, words):
word_counts = {}
for word in words:
word_counts[word] = word_counts.get(word, 0.0) + 1.0
return word_countsWe have a function to clean up our string by removing punctuation, one to tokenize our string into words, and another to count up how many of each word appears in a list of words.
Before we start the actual algorithm, let’s first understand the algorithm. For training, we need three things: the (log) class priors, i.e., the probability that any given message is spam/ham; a vocabulary of words; and words frequency for spam and ham separately, i.e., the number of times a given word appears in a spam and ham message. Given a list of input documents, we can write this algorithm.
- Compute log class priors by counting how many messages are spam/ham, dividing by the total number of messages, and taking the log.
- For each (document, label) pair, tokenize the document into words.
- For each word, either add it to the vocabulary for spam/ham, if it isn’t already there, and update the number of counts. Also add that word to the global vocabulary.
def fit(self, X, Y):
self.num_messages = {}
self.log_class_priors = {}
self.word_counts = {}
self.vocab = set()
n = len(X)
self.num_messages['spam'] = sum(1 for label in Y if label == 1)
self.num_messages['ham'] = sum(1 for label in Y if label == 0)
self.log_class_priors['spam'] = math.log(self.num_messages['spam'] / n)
self.log_class_priors['ham'] = math.log(self.num_messages['ham'] / n)
self.word_counts['spam'] = {}
self.word_counts['ham'] = {}
for x, y in zip(X, Y):
c = 'spam' if y == 1 else 'ham'
counts = self.get_word_counts(self.tokenize(x))
for word, count in counts.items():
if word not in self.vocab:
self.vocab.add(word)
if word not in self.word_counts[c]:
self.word_counts[c][word] = 0.0
self.word_counts[c][word] += countFirst, we can compute the log class priors by counting up how many spam/ham messages are in our dataset and dividing by the total number. Finally, we take the log.
Then we can iterate through our dataset. For each input, we get the word counts and iterate through each (word, frequency) pair. If the word isn’t in our global vocabulary, we add it. If it isn’t in the vocabulary for that particular class label, we also add it along with the frequency.
For example, suppose we had a “spam” message. We count up how many times each unique word appears in that spam message and add that count to the “spam” vocabulary. Suppose the word “free” appears 4 times. Then we add the word “free” to our global vocabulary and add it to the “spam” vocabulary with a count of 4.
We’re keeping track of the frequency of each word as it appears in either a spam or ham message. For example, we expect the word “free” to appear in both messages, but we expect it to be more frequent in the “spam” vocabulary than the “ham” vocabulary.
Now that we’ve extracted all of the data we need from the training data, we can write another function to actually output the class label for new data. To do this classification, we apply Naive Bayes directly. For example, given a document, we need to iterate each of the words and compute $\log p(w_i|\text{Spam})$ and sum them all up, and we also compute $\log p(w_i|\text{Ham})$ and sum them all up. Then we add the log class priors and check to see which score is bigger for that document. Whichever is larger, that is the predicted label!
To compute $\log p(w_i|\text{Spam})$, the numerator is how many times we’ve seen $w_i$ in a “spam” message divided by the total count of all words in every “spam” message.
On additional note: remember that the log of 0 is undefined! What if we encounter a word that is in the “spam” vocabulary, but not the “ham” vocabulary? Then $p(w_i|\text{Ham})$ will be 0! One way around this is to use Laplace Smoothing. We simply add 1 to the numerator, but we also have to add the size of the vocabulary to the denominator to balance it.
def predict(self, X):
result = []
for x in X:
counts = self.get_word_counts(self.tokenize(x))
spam_score = 0
ham_score = 0
for word, _ in counts.items():
if word not in self.vocab: continue
# add Laplace smoothing
log_w_given_spam = math.log( (self.word_counts['spam'].get(word, 0.0) + 1) / (self.num_messages['spam'] + len(self.vocab)) )
log_w_given_ham = math.log( (self.word_counts['ham'].get(word, 0.0) + 1) / (self.num_messages['ham'] + len(self.vocab)) )
spam_score += log_w_given_spam
ham_score += log_w_given_ham
spam_score += self.log_class_priors['spam']
ham_score += self.log_class_priors['ham']
if spam_score > ham_score:
result.append(1)
else:
result.append(0)
return result
In our case, the input can be a list of document texts; we return a list of predictions. Finally, we can use the class like this.
if __name__ == '__main__':
X, y = get_data(DATA_DIR)
MNB = SpamDetector()
MNB.fit(X[100:], y[100:])
pred = MNB.predict(X[:100])
true = y[:100]
accuracy = sum(1 for i in range(len(pred)) if pred[i] == true[i]) / float(len(pred))
print("{0:.4f}".format(accuracy))We’re reserving the first 100 for the testing set, “train” our Naive Bayes classifier, then compute the accuracy.
To recap, we reviewed Bayes Theorem and demonstrated how to use it with an example. Then we re-worked it using hypotheses and evidence instead of just events $A$ and $B$ to make it more specific to our task of spam detection. From there, we derived Naive Bayes by making the Naive Bayes Assumption that each word appears independently of all other words. Then we formulated a prediction equation/rule. Using the Enron dataset, we created a binary Naive Bayes classifier for detecting spam emails.
Naive Bayes is a simple text classification algorithm that uses basic probability laws and works quite well in practice! It is also an important skill set used in the professional industry, so having these skills down pat will have immense implications for your career as well!

