You can access the full course here: Create a Raspberry Pi Smart Security Camera
In this lesson we will discuss a different approach to image-similarity called structural similarity(SSIM). A Mean Squared Error is a really good measure of error difference, but the issue with mean squared error is that it looks at each pixel individually and independently. This is different to how humans perceive images because we don’t look at two images and look at all the pixels of the images and compare them.
We look at the images in a more holistic sense. This is what structural similarity is trying to capture.
So instead of treating it pixel-independently structural similarity actually looks at groups of pixels to try to better determine if two images are different or not.
MSE and SSE look at pixels individually. SSIM looks at groups of pixels, and this is better than looking at pixels individually because then all of those small changes in noise and variation don’t tend to affect groups of pixels than they do with individual pixels.
As it turns out that some structural similarity is actually a product of three other kinds of measures.
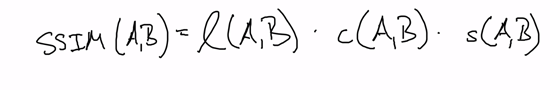
The L stands for luminance, C is for contrast, and S is for structure.
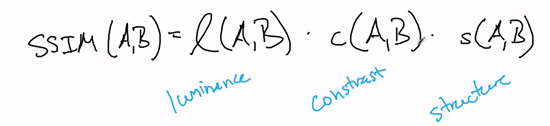
When you look at groups of pixels, then you get a better representation of the image and a better representation subsequently of the difference between images when you look at groups instead of just one individual pixel.
The good thing about structural similarity and its much different than MSE, or SSE, is that it actually has a lower and upper bound.

Transcript
Hello everybody. My name is Mohit Deshpande, and in this video I want to discuss a different approach to emit similarity called structural similarity.
And so a mean squared error is a really good measure of error difference, but the issue with mean squared error is that it looks at each pixel individually and independently. And this is different to how humans perceive images because we don’t look at two images and look at all the pixels of the images and compare them. We look at the images in a more holistic sense. And so this is what structural similarity is trying to capture.
Well, humans looks at images more holistically and structural similarity tries to capture this using statistics. And that’s the issue with mean squared error is we’re just looking at all of the pixels. And as humans, we don’t do that. We can’t see all of the small variations and noises in our image, and overall it doesn’t really matter. If we show you two images and one of the images has all the pixels that are just shifted by like one value, then you’re probably not gonna see, you’re probably not gonna notice the difference at all, and you’ll say, well, these two images are exactly the same.
But mean squared error will see it, and it will pick that up. So instead of doing these pixel-wise independently, of treating it pixel-independently, structural similarity actually looks at groups of pixels to try to better determine if two images are different or not. And so, let me actually write this down. That MSE, and also sum of squared error, if you choose to use that, they look at pixels individually. Look at pixels individually. But with structural similarity, that’s a terrible S. Third time’s a charm. There we go, yeesh.
With structural similarity, we look at groups of pixels. So groups of pixels. And this is a bit better than looking at pixels individually because then all those small changes in noise and variation don’t tend to affect groups of pixels than they do with individual pixels.
And as it turns out that some structural similarity is actually a product of three other kinds of measures. So let me actually write out structural similarity. So structural similarity between an A and B is actually a product of some other things. It is a product of, L of AB times C of AB times S of AB, and I’m gonna explain what these are in just a second. So L stands for luminance. So, luminance. C is contrast, and S is structure.
And I’m not actually gonna expand this out because there’s an actual formula dealing with individual pixels and actually with groups of pixels using statistics like the mean and variance. And I actually don’t wanna expand that out because that kind of gets more into statistics and histograms and stuff that I don’t really want to get into that much. It requires a pretty decent amount of knowledge about statistics.
But A and B, it turns out that when you look at groups of pixels, then you get a better representation of the image and a better representation subsequently of the difference between images when you look at groups instead of just an individual pixel. And so we look at things like, we look at the histogram basically. We look at the averages of pixels. We look at the spread of a group of pixels, and all of these measurements use statistics to actually determine similarity. We get kind of a better idea of the difference between the images when we look at groups instead of just individual pixels. In the next video, I’m actually gonna show you why this a bit better. And this is slightly more representative of how humans perceive images.
And there’s more topics to discuss about that that we won’t be able to get into, but structural similarity is a really good measure of image difference. And the good thing about structural similarity and it’s much different than MSE, mean squared error, or sum squared error is that it’s actually has a lower and upper bound. So what I mean by that is, let me just use a different color here, is that structural similarity is always between minus one and one. Where positive one is perfect match and minus one we’re not gonna talk too much about but, minus one means that it is imperfect.
Or I should say it is perfectly imperfect, and that just has to deal with the way that the stats works out, but we usually don’t consider this realm here. We’re just more concerned about this realm. So the closer that the result of structural similarity, and it returns a number just like mean squared error and sum squared error, the closer it is to one, the closer two images are to being related, or I should say, the closer the two images are to being exactly the same. ‘Cause if I have a structural similarity index, I get the value back, it’s one, then I know that these two images are exactly the same. If it’s a little less than one, then I know that well, they’re a little bit different.
And so this kind of works in a similar fashion as mean squared error, but if you notice, mean squared error actually doesn’t have an upper bound. Besides barring any sort of bounds that you put on the pixel values themselves, mean squared error just has a lower bound of zero, and then it could be any large number after that. But with structural similarity, it’s always between minus one and one, and that’s really nice.
And so I think this is where I’m going to stop this video, and we’re actually going to see an example of structural similarity and how it compares to mean squared error in the next video. And don’t worry, we won’t have to implement this at all, even using non-py because as it turns out there’s this library under, well it’s a component of SciPy. It’s called a scikit image, or I should say it’s a clone of scikit, not necessarily SciPy. At a component of scikit called scikit image, and it actually just gives us a function called SSIM. And you just pass it two images, and it computes a value. So it looks almost exactly like this. And it has other parameters, but we don’t actually have to implement it. We don’t have to know what these are. We just can pass it into the function there and run it.
But anyway, I’ll stop right here, and I’ll just kind of do a quick recap. So with structural similarity, we try to take a different approach to considering image similarity, and that is we look at groups of pixels and perform statistics on those groups, rather than looking at each pixel individually like mean squared error or sum squared error does. And looking at groups is a bit better because it’s more representative to how humans view images. And so any of the small tiny variations in the image that mean squared error will pick up, structural similarity actually will account for that.
And so, structural similarity is also generally a better approach to image similarity, although at some cost. Another important thing that I want to mention is that structural similarity also has a defined range. It goes between minus one and one, that’s it. Mean squared error, it starts at zero ’cause it’s an error metric, but beyond that point, we don’t know what the upper bound necessarily is, barring any sort of limits that we place on the pixel values.
But anyway, we’re going to look at how we can, we’re gonna compare structural similarity and mean squared error in the next video and look at how we can call structural similarity using that scikit image library. So we’ll get to all that good stuff in the next video.
Interested in continuing? Check out the full Create a Raspberry Pi Smart Security Camera course, which is part of our Python Computer Vision Mini-Degree.