You can access the full course here: Bite-Sized SQL
Part 1
In this lesson you will learn how to setup the development environment.
For managing our dependencies we are going to use this tool called “Anaconda.” Essentially you can use Anaconda to manage our dependencies and update them very easily.
You can download Anaconda from here: https://www.anaconda.com/
The direct link is here: Anaconda Download
Choose the version of Anaconda you need based on your current operation system you are using.
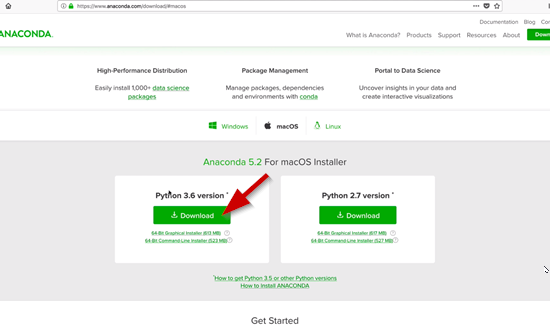
Once you have Anaconda downloaded go ahead and follow the setup wizards instructions.
Once Anaconda is installed go ahead and open the Anaconda Navigator application.
Once Anaconda is opened on your system it should look similar to this:

This already has all our dependencies bundled into these things called environments.
So select the Environments Tab from the Anaconda menu.
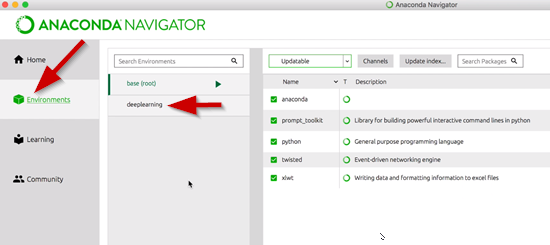
At the bottom you can see a tool bar to create and import environments.
You can change your environment by clicking on one of them in the menu. So if you clicked on the deeplearning one, you will then see all of the installed packages listed on the right.
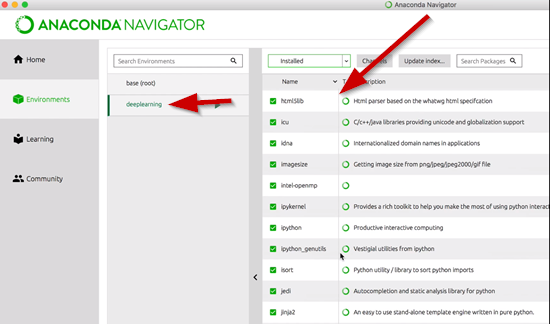
In the projects that we will be working on for this course, you will be provided with an environment file. All you will need to do is import that environment file that was provided and then it will create the environment, download all the dependencies packages and install them.
You can download the environment file from the Course Home page (NOT AVAILABLE IN FREE WEBCLASS).
The file is called “my-awesome-project.zip” and once you have it downloaded you will need to extract it. Once extracted you will have one single file called “environment.yml”
The environment.yml file contains all of dependencies of the Python packages and the version numbers.
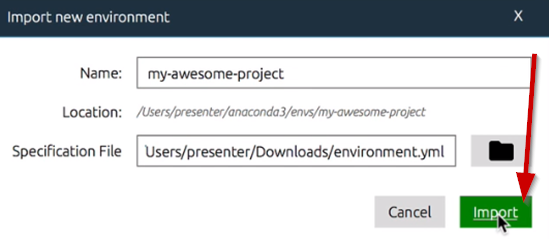
All we need to do now is import the environment file. From the Anaconda Navigator menu, go to Import, and that will pull up a window for you to select the environment file you now have and name it and then click the import button.
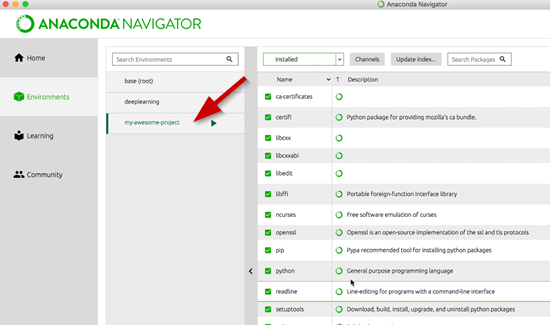
After its done loading you will now see it in the list to choose:
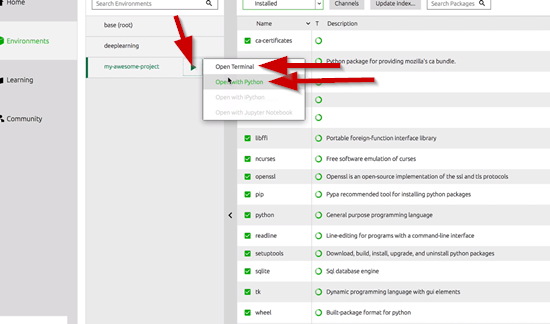
If you click on the green arrow next to the my-awesome-project you will pull up a drop down menu, and from this menu you can open the terminal or with Python.
Part 2
What is a Database
A high level definition of a database is that it is a highly efficient way of storing data for querying and data management. Querying is asking questions about the data I have. Another way to look at databases visually is to think of them as a spreadsheet workbook such as below.
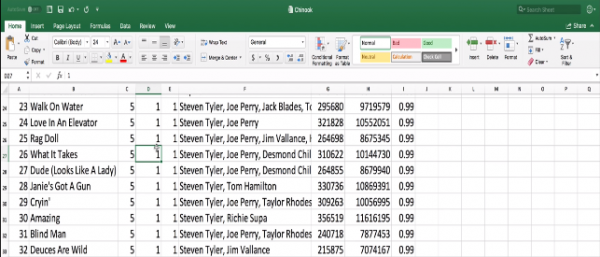
A worksheet may have many sheets such as Track, Album etc. representing data from music tracks and the album they are part of. In database lingo, these would correspond to two different tables.
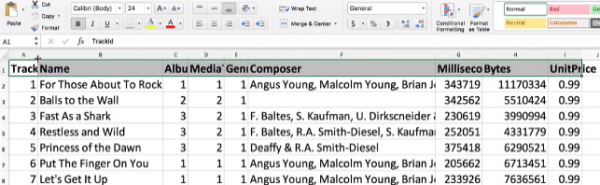
In the worksheet above, the header row (highlighted) tells us what fields(similar to columns in a database table), are present in the data. The worksheet rows below the header contain the actual entries (similar to rows in a database table).
Here are the header row (columns) and entries (rows) from the Track sheet (table).
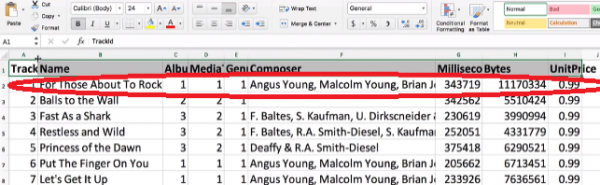
Track, Name, Album, Media, Genre, Composer etc. represent database columns e.g. the Composer column contains names of all the composers for the various tracks. The data in the entries below the columns (such as the red highlighted entry) represent rows.
Conceptually we can think of data in a database as being organized as in the spreadsheet where each sheet represents a table, the sheet header represents the columns and the sheet entries represent rows. Databases are really fast and efficient at storing and retrieving millions of rows and we will soon see an experiment that demonstrates the huge time difference between using a database to answer a query versus using a CSV or text file to answer the same query.
Managing Data
We manage data in a database using SQL (Structured Query Language), also pronounced sequel. We can use SQL to query the database for data, add rows, change or delete rows. We can also use it to create new tables.
Kinds of Databases
There are several kinds of databases. We will be looking at SQLite (https://www.sqlite.org/index.html), which is really simple and easy to set up and use out-of-the-box. It’s size and compactness makes it very popular in mobile application development on platforms such as iOS and Android. Different databases may have their own proprietary operators. However the SQL we are going to write here for SQLite is transferable to to larger databases such as mySQL as well. mySQL is very popular in industry applications.
Why Databases, Experiment
Its worthwhile discussing why we need a database for storage with SQL for querying as opposed to just using a CSV file. Lets look at an experiment where we compare these approaches by using python scripts to retrieve data (list of orders) from a SQLite database Vs a CSV file. Both the database (single table) and the CSV file have the same order information (approximately 500,000 entries – a small number in comparison to large commercial databases).

data.csv – order data in CSV format
example.db – order data in SQLite format
db.py – script that retrieves data from example.db
text.py – script that retrieves data from data.csv
The query we will be using is a very classic commonplace query used all the time while buying from a website : Fetch me the order whose id is <order_id>. We will be using python to ask both the text file and the database for this information. In the case of the database, we will use the python SQLite API. We will time both these approaches using the UNIX time command. The results are below.
CSV file
$ time python3 txt.py

The query takes roughly 2000 ms.
SQLite Database
$ time python3 db.py

The SQLite query takes about 64 ms. We can see the huge difference in retrieval time between using a text file Vs a database for just 500,000 rows. People use databases with millions of rows in the industry. Databases thus store data very efficiently thus allowing us to perform very powerful queries against the data stored. This is why we use databases.
Transcript 1
Hello, world, and thanks for joining me. My name is Mohit Deshpande, and in this course we’ll be learning about querying databases. The databases are ubiquitous and pretty much everything that we do nowadays, every time you go to a website, odds are there’s a database running somewhere on the backend that’s helping manage all of your data. Definitely anytime you log into the website, there’s databases going on that has all your login credentials and managing all that information.
So they’re ubiquitous, especially in a company, any kind of large company you’ve heard of, they definitely have and use a database on a regular basis. It’s kind of the backbone infrastructure of their entire operation, and we’re gonna be learning how we can query these databases.
So, primarily we’re gonna be focused on how we can query data. In other words, how can we ask questions about the data that we have stored in our database. So we can do interesting things like ask our database to retrieve a list of all of our purchases that we’ve made over the past six months that have cost more than $35. This is a kind of example query that you might hear about when you visit any kind of retail site, and this is what we’re gonna be learning about.
We’ll learn about how to query data, and we’ll learn about how we can do different kinds of sorting of the data that we already have. We’ll learn about grouping and aggregation, and then finally how we can take data from multiple, we can take different kinds of data and merge it into one combined information across different databases.
We’ve been making courses since 2012, and we’re super excited to have you on board. Online courses are a fantastic way to learn new skills, and I take a lot of online courses myself. And the courses consist mainly of video lessons that you can watch and rewatch as many times as you want. We also have downloadable source code and pocket files and they contain everything that we’re working on during the lessons.
It’s highly recommended that you code along with me. In my experience, that’s the best way to learn something – to get your feet wet, so to speak. And lastly, we’ve seen that students who get the most out of these online courses are those who make a weekly plan and stick to it, depending on your own availability and learning style, of course.
So Zenva, over the past six years or so, has taught all different kinds of topics on programming and game development to over 300,000 students over 100 courses. The skills that they’ve learned in these courses and guides are completely transferrable to other domains, as well. In fact, some of the students have used these skills to advance their own careers, to start a company, or to publish their own content from the skills that they’ve learned. Thanks again for joining, and I look forward to seeing all the cool stuff that you’ll be doing.
Now without further ado, let’s get started.
Transcript 2
So for managing our dependencies, we’re gonna use this really awesome tool called Anaconda. Anyway, we go anaconda.com. On the right here there’s this green button called Downloads. So we go to Downloads. You wanna download the right one. This is the latest version of Python that we have. So we’ll click Downloads and that’ll install both of the steps and it will install Anaconda.
And we’ll get this application called Anaconda Navigator. It’ll look kinda something like this. You might not have the same packages as I do installed. This already has all of our dependencies bundled into these things called environments – that I’ve already mentioned.
So let’s go ahead and go over to the environments. And you’ll see. I already have one for deep learning that I like to use. Here is list of environments. And bottom here, there’s buttons to create and import an environments. You can change which environment you are using. In other words, you’re changing all the dependencies that you have just by clicking on one of these guys. And you’ll see that we will have changed our environment.
So now they are here all. I go installed. Here are all of the packages. All the dependencies and packages, Python packages that I use for deep learning for example. We’ll have an environment file for you to download. So in this case, this is a Zip file called my-awesome-project.zip. And let me open that guy up. So you’ll want to extract this guy here.
Okay so inside of this Zip file there’ll be a single a file called environment.yml. In Anaconda navigator, we’ll import. And then it’ll pull up this little dialogue box that says File to import from. Just click on this little folder icon. And then navigate to the environment.yml file. And I just click on this. Click open and you’ll see it’s loaded up with the appropriate name, and I can just click import and in just a minute or so, all update dependencies and packages will be downloaded and installed in my environment.
One other thing that all discussed before we go is – you see this little green arrow. If we click on that, you’ll see we’ve got a couple of options here we would say. Open Terminal or open with Python. Those that either savvy with the Terminal, notice when I open Terminal, what will happen is I get a Command Prompt that’s already set up to use my-awesome-project. You can use this for. If you doing any kind of command line stuff with Python. In our environment, is where you want all of the dependencies to be working. All you have to do is click the green arrow and go to Terminal.
Transcript 3
So first of all, is what is a database? A database is a very efficient way to store highly structured data for querying and data and data management. What I mean by querying is really just question and answering, so I have a ton of data and I wanna ask a question about it. You can conceptually think of the data stored inside of a database as being kind of like in a workbook like this. With a workbook, we have these different, down here at the bottom, you can see we have two different sheets.
In database lingo, these would be considered two different tables. We have a hetero here that tells me what each of the entries looks like, just like we would expect in a regular table. Database lingo also uses the same conceptualization of rows and columns. So a row would be a slice this way, and rows are just entries inside of these tables. And then columns represent slices across all of the rows. So here’s a Composer column and inside of this column, has all of the different composers.
There are a ton of different kinds of databases. The one that we’re gonna be looking at is called SQLite, or SQLite. So I have a little experiment, an example.db SQLite file, and I have a data.csv, which is just a text version of this database and a two Python scripts just to make it fair. And this db.py, what it’s going to do is run the query against this database, and the txt.py is gonna run a query against the CSV file which is this plain text. So the query that we’re asking – so this database, by the way, I should mention that the database and CSV contain a list of different orders.
And so the question I’m gonna ask is if it would fetch me all the information you can about the order whose ID is blank, and whatever the order ID I chose. So we’re gonna time both of these and see how long it takes.
So let’s first time the TXT file. So there’s UNIX command time that I can just run, time python3 txt.py. So if you run this guy, the real-time is how much time, like a wall clock, it’s called wall clock time, so how much time has elapsed overall. So we see it’s about two seconds. And we can convert this into milliseconds so it’ll be useful. So it’s about 2,000 milliseconds. So that’s how long it would take. And I should mention that the number of rows we have in this table that we’re running the query against is a little over half a million rows, which we’ll keep that in mind.
Now I’m gonna show you how fast we can get this working using the database. So I can run this guy, and you see this? Not even one second, not even .1 seconds, but it ends up taking 64 milliseconds. So you can this huge difference between using a TXT file and using a database.
Interested in continuing? Check out the full Bite-Sized SQL course, which is part of our Bite-Sized Coding Academy.
