Although deep learning has great potential to produce fantastic results, we can’t simply leave everything to the learning algorithm! In other words, we can’t treat the model as some black-box, closed entity that can read our minds and perform the best! We have to be involved in the training and design process to make sure our model is learning efficiently. We’re going to look at several different techniques we can apply to every deep learning model that will help improve our model’s accuracy.
Overfitting and Underfitting
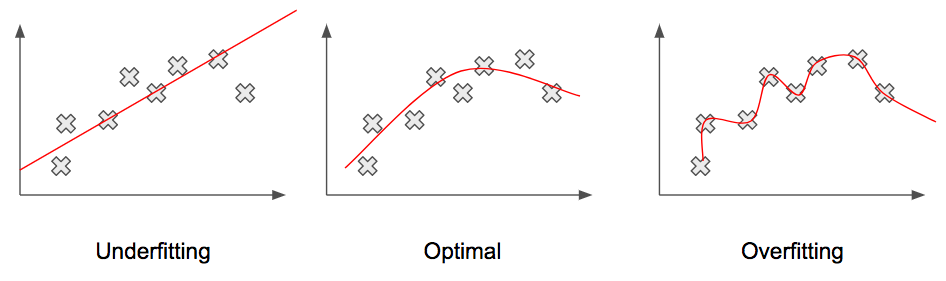
To discuss overfitting and underfitting, let’s consider the challenge of curve-fitting: given a set of points, find the curve of best fit. We might think that the curve that goes through all of the points is the best curve, but, actually, that’s not quite right! If we gave new data to that curve, it wouldn’t do well! This problem is called overfitting. Why we’re discussing it is because it is very common in deep architectures. Overfitting happens when our model tries so hard to correctly classify each and every example, that it ends up modeling of all of these tiny noises and intricacies for each input. Then, when we give it new data it hasn’t seen before, the model doesn’t know what to do! We say it generalizes poorly! We want our model to generalize to new, never-before-seen data. If it overfits, then we’ll get poor accuracy on new data.
Overfitting is also related to the size of the model and is, therefore, a huge problem in deep learning where we have millions of parameters! The more parameters we have, the better we can fit the data. Specifically for curve-fitting, we can perfectly fit a curve to N number of points using an N-1 degree polynomial.
There are several ways to detect overfitting. We can plot the error/loss of the training data and the same for the validation set. If we see that our training loss is very small, but our validation set loss is still high, this is an indication of overfitting. Our model is doing really well on the training set but is failing to generalize. Another, similar, indication is the training set and testing set accuracy. If our model has a very high training set accuracy and very low test set accuracy, this is an indication of overfitting for the same reason: our model isn’t generalizing! To combat overfitting, we use regularization. We’ll discuss a few techniques later.
The reciprocal case to overfitting is underfitting. This is less of a problem in deep learning but does help with model selection. In the case of underfitting, our model is generalizing so much that it’s actually missing the underlying relationship of the data. In the figure above, the line is linear when the data are clearly non-linear. This type of generalization also leads to poor accuracy!
To detect underfitting, we can look at the training and validation loss. If both are high, then we know that our model is underfitting. To prevent underfitting, we can simply use a larger model! If we have a 2-layer network, we can try increasing the number of hidden neurons or try adding more hidden layers. Both of these will help increase the number of parameters of our model and prevent underfitting.
This problem of overfitting and underfitting is called the bias-variance dilemma or tradeoff in learning theory. We’re referring to the bias and variance of the model, not the actual bias or variance of the parameters! The bias and variance represent how much we pay attention to the model data itself. If we have a high-variance model, this means we’re paying too much attention to the intricacies of the data. A high-bias model means we’re ignoring the data entirely. The goal is to build a model with low bias and low variance.
We can explain overfitting and underfitting in terms of bias and variance. If we have an overfit model, then we say this is a high-variance model. This is because the overfit model is learning the tiny intricacies and noise of the data. An underfit model is a high-bias model because we’re completely missing and ignoring the underlying structure of the data.
To summarize, we can look at the training and testing loss to determine if our system is underfitting or overfitting. If both losses are high, then our model is underfitting, and we need to increase the number of parameters. If our training loss is low and our testing loss is high, then our model is overfitting and not generalizing well. In this case, we can use regularization to help prevent overfitting. Let’s discuss a few techniques!
Dropout
Dropout is a technique that was designed to counteract overfitting. In fact, the paper that introduced it is titled Dropout: A Simple Way to Prevent Neural Networks from Overfitting by Srivastava et al. In the paper, they present a radical new way to prevent overfitting and improve generalization.
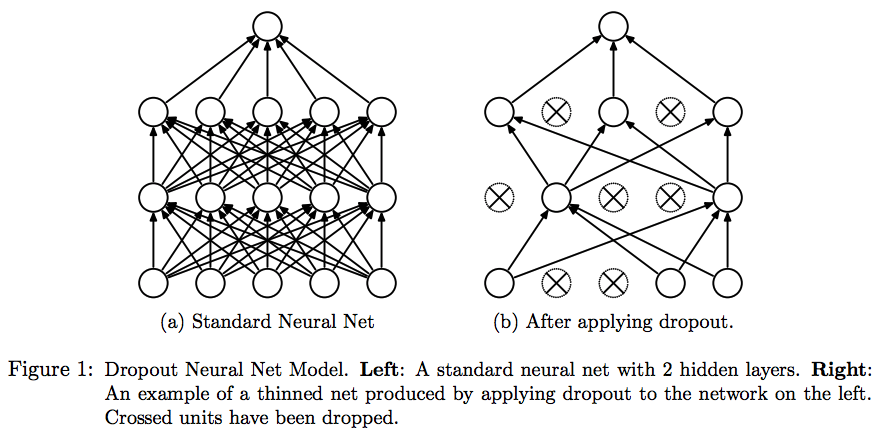
(Dropout: A Simple Way to Prevent Neural Networks from Overfitting by Srivastava et al.)
The idea behind dropout is to randomly zero out some of the weights in a given layer. When we do this, we effectively “kill” that neuron. Then, we continue with the regular training process for each example in a mini-batch. The figure above is taken from the paper and pictorially explains this nullification.
Mathematically, each layer that has dropout enabled, which won’t be all layers, will have dropout neurons that each have some equal probability of being dropped out. For example, in the above 2-layer network, each neuron in the second hidden layer has a probability of being dropped out. For each example in each mini-batch, we drop out some neurons, pass the example forward, and backpropagate with the neurons still dropped out! This is the critical point: the neurons that were dropped out in the forward pass are also dropped out in the backward pass. Remember that neural networks learn from backpropagation. If we didn’t also drop out the same neurons during the backward pass, then dropout wouldn’t do anything! During testing, however, we enable all of the neurons.
This was a bit of a radical technique when it was introduced. Many researchers asked, “how could something like this help the network learn?” There is an intuition behind why this works: by thinning the network, preventing it from using all of the neurons, we force it to learn alternative or redundant representations because the network can never know which neurons will be unavailable for it to use.
As great as this technique sounds, let’s not be dropout-happy and apply it to each and every layer! There are a few instances where we don’t use dropout. For example, we never apply dropout in the output layer. This is because the output neurons produce a probability distribution over all of the classes. It doesn’t make sense to drop out any neurons in this layer because then we’re randomly ignoring some classes!
Dropout has implementations in almost all major libraries, such as Tensorflow, Keras, and Torch. For example, the following line of code in Keras will add Dropout to the previous layer with a dropout probability of 0.5.
model.add(Dropout(0.5))
In most cases, a dropout probability of 0.5 is used. This regularization technique of dropout is very widely used in almost all deep learning architectures!
There is one minor point to discuss when implementing dropout: output scaling. During training, we have to scale the outputs of the neurons. This is because we need to ensure that the training and testing phases’ activations are identically scaled, because, during testing, all neurons receive all inputs while, during training, a fraction of neurons see the inputs. However, since testing-time performance is very important, we often implement dropout as inverted dropout where we scale during training instead of testing.
Weight Regularization
There are two other types of regularization that are a function of the parameters or weights themselves. We call these  and
and  regularization. These correspond intuitively to weight sparsity and weight decay. Both of these regularizers are attached to the cost function with a parameter
regularization. These correspond intuitively to weight sparsity and weight decay. Both of these regularizers are attached to the cost function with a parameter  that controls how much emphasis we should put on the regularization.
that controls how much emphasis we should put on the regularization.
![\[ C = E + \lambda R(W) \]](https://gamedevacademy.org/wp-content/ql-cache/quicklatex.com-6b71fddb0086bd9b296b14f21f591ce6_l3.png "Rendered by QuickLaTeX.com")
Here,  is a cost function where
is a cost function where  computes the error using something like squared error, cross entropy, etc. However, we introduce another function
computes the error using something like squared error, cross entropy, etc. However, we introduce another function  that is the regularizer and the parameter. Since our new cost function is a sum of two quantities with a preference parameter , our optimizer is going to perform a balancing act: minimize the error while also obeying the regularizer. In other words, the regularizer expresses a preference to do something. In the case of regularization, we’re going to prefer the optimizer to do something with respect to the weights. Let’s discuss the types of regularization!
that is the regularizer and the parameter. Since our new cost function is a sum of two quantities with a preference parameter , our optimizer is going to perform a balancing act: minimize the error while also obeying the regularizer. In other words, the regularizer expresses a preference to do something. In the case of regularization, we’re going to prefer the optimizer to do something with respect to the weights. Let’s discuss the types of regularization!
We’ll first discuss regularization, shown below. This is also called weight sparsity because of what it tries to do: make as many weight values 0 as possible. The idea is to add a quantity to the cost function penalizes weights that have nonzero values. Notice that  when all of the weights are zero. However, the network wouldn’t learn anything in this case! This prevents us from ever reaching the case where . In other words, the regularizer prefers many zero weights. This is called weight sparsity. An interesting product of regularization is that it acts as a feature selector. In other words, due to sparsity and the preference to keep zero weights, the weights that are nonzero are very important because they would have been set to zero by the optimizer otherwise!
when all of the weights are zero. However, the network wouldn’t learn anything in this case! This prevents us from ever reaching the case where . In other words, the regularizer prefers many zero weights. This is called weight sparsity. An interesting product of regularization is that it acts as a feature selector. In other words, due to sparsity and the preference to keep zero weights, the weights that are nonzero are very important because they would have been set to zero by the optimizer otherwise!
![\[ R(W) = \displaystyle\sum_k |w_k| \]](https://gamedevacademy.org/wp-content/ql-cache/quicklatex.com-f9320be47b94529b1e184c3cb0be1361_l3.png "Rendered by QuickLaTeX.com")
Now let’s move on to regularization, shown below. This is sometimes called weight decay. Although they are technically different concepts, the former being a quantity added to the cost function and the latter being a factor applied to the update rule, they have the same purpose: penalize large weights! This regularizer penalizes large weight values by adding the squared size of all of the weights to the cost function. This forces our optimization algorithm to try to minimize the sum of the squared size of all of the weights, i.e., bring them closer to zero. In other words, we want to avoid the scenario where a few weights have really large values and the rest of the weights are zero. We want the scenario where the weight values are fairly spread out among the weights.
![\[ R(W) = \displaystyle\sum_k w_k^2 \]](https://gamedevacademy.org/wp-content/ql-cache/quicklatex.com-75de853fea3e97003d15fc12da3b0d0b_l3.png "Rendered by QuickLaTeX.com")
One more point regarding weight decay and regularization. Although they are conceptually different, mathematically, they are equivalent. By introducing regularization, we’re decaying the weights linearly by a constant factor during gradient descent, which is exactly weight decay.
Like dropout, all major libraries support regularization. In Keras, we can add regularization to weights like this.
model.add(Dense(1024, kernel_regularizer=regularizers.l2(0.01))
In this case, we’re using Regularization with a strength of 0.01. In practice, the most common kind of regularization used is Regularization and Dropout. Using these techniques, we can prevent our model from overfitting and help it generalize better!
We’ve covered some important aspects of applied deep learning. We discussed this problem of underfitting and overfitting and the bias-variance dilemma/tradeoff. Overfitting is more common in deep learning because we often deal with models with millions of parameters. We discussed a technique called Dropout that can help us prevent overfitting. The idea is to drop out neurons for each dropout layer. This forces our network to learn redundancies when training. During testing, we give all neurons all inputs again. We also looked at two other types of regularization that produce interesting weight characteristics: and regularization. The former produces sparse weights and acts a feature selector: we have many zero weights, and the nonzero weights are the most important features. With the latter flavor of regularization, we prefer diffuse weights to a few weights with large values. This is similar to the technique of weight decay and reduces to the same thing mathematically.
The concept of regularization is widely used in deep learning and critical to preventing model overfitting!


